…
[ad_1]
Di blogpost ini, saya akan membagikan pembelajaran saya tentang kemampuan pemrosesan JSON dari Oracle Database. Dataset saya berisi 1,5 juta tweet yang dikumpulkan selama 2 hari untuk satu set token (lebih lanjut tentang token di kemudian hari di posting ini). Dan IMO itu mewakili ukuran yang baik dari dataset dunia nyata untuk eksperimen daripada memiliki tabel dengan hanya beberapa baris data JSON yang diejek. Dataset telah dikumpulkan menggunakan API streaming Twitter.
Ukuran dan versi database
Saya memilih layanan cloud basis data 12CR2 di Oracle Cloud untuk analisis ini. Ini memiliki 2 OCPU (2 core intel) dan 30 GB memori. Memori 11GB telah dialokasikan untuk SGA.
Sumber data
Seperti disebutkan di atas sumber data adalah aliran Twitter yang difilter untuk token berikut.
Merek sepatu – Nike, Reebok, Adidas
Bank – UBS, Barclays, HSBC
Merek teknologi – Google, IBM, Microsoft, Oracle, MongoDB, DataStax
Pengaturan Objek Database dan Pemuatan Data
Kami membutuhkan tabel eksternal dan memetakan file yang berisi tweet. Dan tabel permanen untuk kemudian memuat data dari tabel eksternal ke tabel permanen. Tabel permanen opsional karena kueri SQL yang sama dapat dieksekusi terhadap tabel eksternal.
CREATE DIRECTORY twitter_data as '/u01/app/oracle/tweets'; CREATE TABLE tweet_external_table (tweet clob) ORGANIZATION EXTERNAL (TYPE ORACLE_LOADER DEFAULT DIRECTORY twitter_data ACCESS PARAMETERS (RECORDS DELIMITED BY 0x'0A' DISABLE_DIRECTORY_LINK_CHECK FIELDS (tweet CHAR(32000))) LOCATION (twitter_data:'twitter_data.json')) PARALLEL REJECT LIMIT UNLIMITED; CREATE TABLE tweet_table ( id VARCHAR2(32) NOT NULL PRIMARY KEY, date_loaded TIMESTAMP(6) with TIME ZONE, tweet CLOB CONSTRAINT ensure_json CHECK (tweet IS JSON)) LOB (tweet) STORE AS (CACHE);
Perhatikan batasan periksa dalam definisi tabel di atas. Ini memungkinkan untuk menyaring titik data yang cacat atau tidak lengkap.
Memuat data di tabel database Oracle
Insert into tweet_table (id, date_loaded, tweet) Select SYS_GUID(), SYSTIMESTAMP, tweet from tweet_external_table WHERE tweet is JSON; Commit;
Periksa jumlah baris di tweet_table untuk mengonfirmasi bahwa saya memiliki 1,5 juta tweet.
SELECT count(*) from tweet_table; COUNT(*) ---------- 1550931
Menganalisis dokumen JSON menggunakan notasi 'Dot' dan ekspresi jalur SQL/JSON
Sekarang saya memiliki data Twitter dalam database, saya akan menjalankan tiga analisis dasar berikut pada set data ini menggunakan notasi 'DOT' dan kemudian menggunakan ekspresi JSON_QUERY dan JSON_VALUE.
Analisis #1 – Distribusi tweet per bahasa
Perhatikan bahwa nama kolom tempat JSON disimpan disebut 'tweet'. Menggunakan notasi 'DOT' di SQL, Anda dapat melintasi dokumen JSON dengan mudah. Saya pikir ini cukup kuat untuk orang yang akrab dengan SQL. Setara dalam bahasa pemrograman lain dapat dengan mudah menjadi beberapa baris kode.
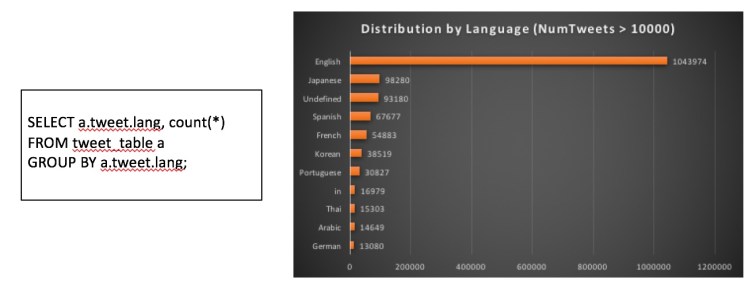
Dan kueri yang sama dapat ditulis menggunakan ekspresi SQL/JSON seperti yang ditunjukkan di bawah ini:
SELECT lang, count(*) NumTweets FROM ( SELECT json_value(tweet, '$.lang') lang FROM tweet_table ) GROUP BY lang;
Analisis #2 – Distribusi tweet per negara.
Objek tweet berisi informasi lokasi hanya jika ditandai secara geo. Dalam dataset saya, saya perhatikan bahwa sejumlah besar tweet tidak memiliki data lokasi yaitu nilai dalam tag tweet.place.country adalah nol. Untuk alasan ini, saya telah merencanakan distribusi tweet per negara sebagai persentase dari total tweet geo-tag.
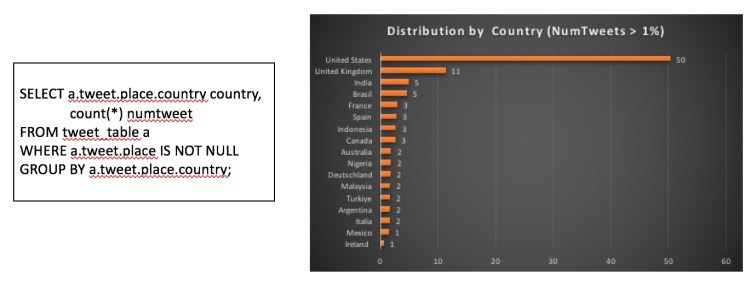
Dan kueri yang sama dapat ditulis menggunakan ekspresi SQL/JSON seperti yang ditunjukkan di bawah ini:
SELECT country, count(*) NumTweets FROM ( SELECT json_value(tweet, '$.place.country') country from tweet_table) GROUP BY country;
Analisis #3 – Distribusi tweet untuk setiap token yang dikumpulkan.
Akhirnya, periksa distribusi tweet di semua token yang telah saya kumpulkan dalam periode 2 hari. Pernyataan kasus dalam SQL jika digunakan untuk kategorisasi berdasarkan tweet_text. Saya memiliki lebih dari 700 ribu dengan tag 'tidak diketahui' yaitu tidak ada token yang ingin dikumpulkan skrip data saya. Saya perlu memeriksa mengapa tweet ini dikumpulkan, tetapi itu tidak ada dalam ruang lingkup posting blog ini.
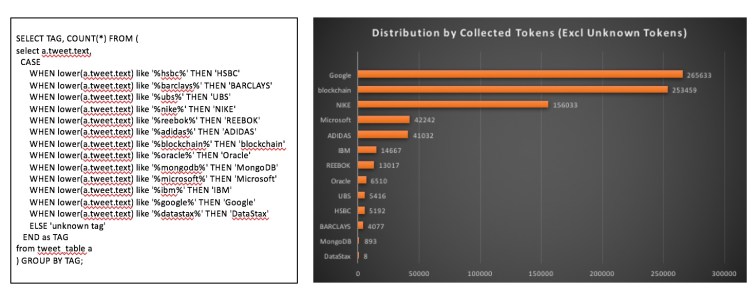
Menyadari
Saya perhatikan bahwa notasi titik tidak berfungsi jika salah satu tag dalam dokumen JSON adalah Oracle Reserve Word. Misalnya, saya tidak dapat mengakses detail “pengguna” dari tweet menggunakan notasi dan kesalahan 'DOT' ditunjukkan di bawah ini. Namun, itu bekerja dengan baik dengan ekspresi JSON_VALUE SQL/JSON
select a.tweet.user from tweet_table a * ERROR at line 1: ORA-01747: invalid user.table.column, table.column, or column specification
Menggunakan ekspresi JSON_VALUE:
select json_value(tweet, '$.user.name') username, json_value(tweet, '$.user.followers_count') followers_count from tweet_table;
Tujuan dari posting blog ini adalah untuk menyoroti kemampuan penyimpanan dan permintaan Oracle 12c untuk data JSON. Ini tidak termasuk tolok ukur atau pengujian kinerja. Ada lebih banyak kemampuan pemrosesan JSON dalam database Oracle daripada yang saya tulis dan tunjukkan dalam posting blog ini. IMO, ada baiknya membaca dokumentasi dan mengeksplorasi kemungkinan.
Akses ke data tweet
Saya dapat membagikan dataset jika Anda ingin menggunakannya untuk eksperimen Anda sendiri. Ukurannya terkompresi adalah 1.1GB.
Referensi:
Tautan berikut memberikan informasi lebih lanjut tentang pemrosesan JSON serta memahami objek tweet.
[ad_2]
…